AI Helped Me Decide Which AI Sounds Best

Three voices, three price tags — can you spot the one that costs less than a dollar for a million tokens?
- The first voice belongs to a fresh startup that just closed a $64 million Series A and lists its API at roughly $50 per million.
- The second one is an open‑weight model you can run for about $0.80 per million characters.
- The last voice comes from a company that has raised $281 million in venture funding and bills around $150 per million characters you generate.
I don't know about you, but I found this situation interesting and explored different speech synthesis models.
Benchmarking Text-to-Speech Models
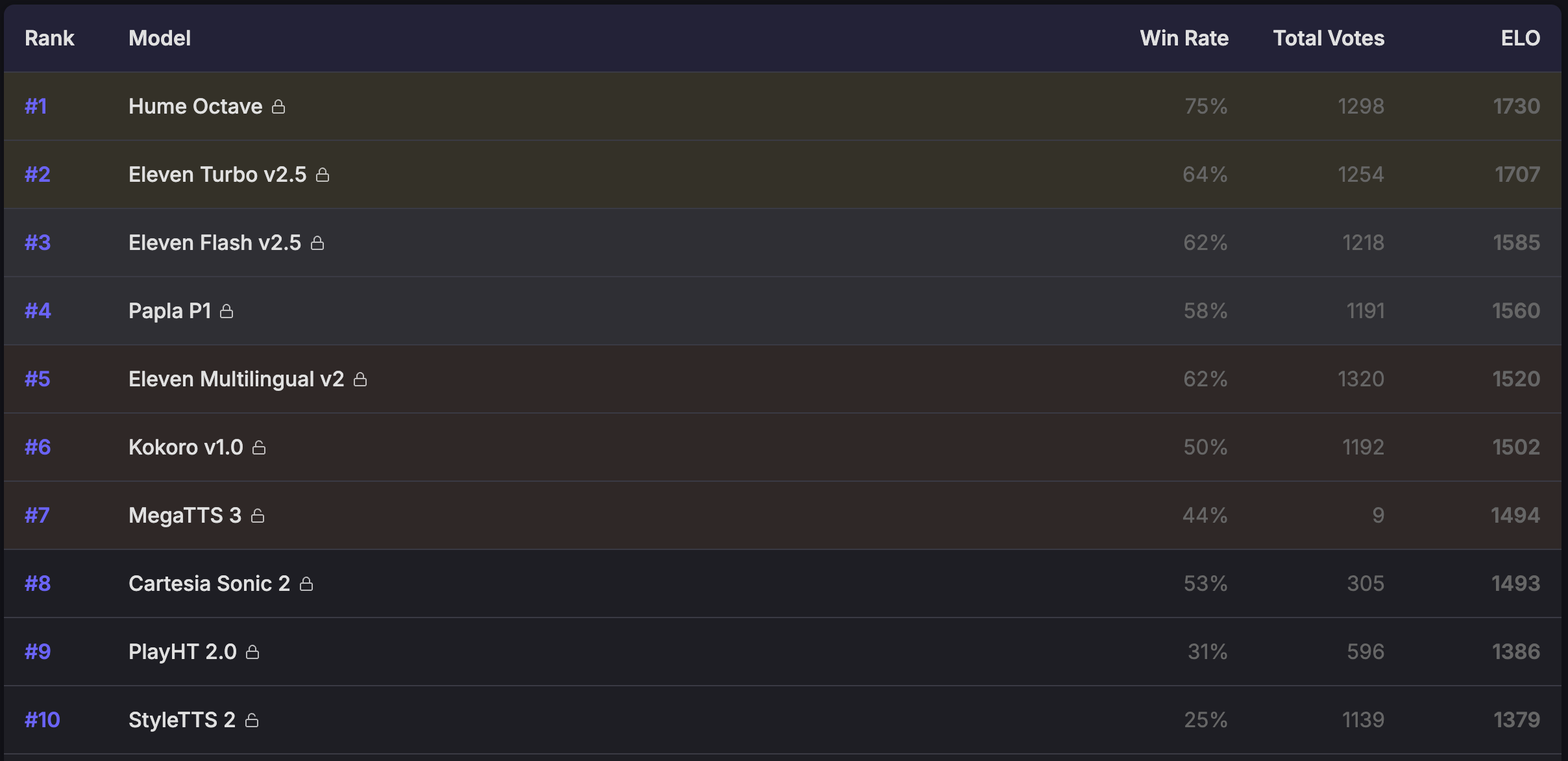
There's a vast variety of TTS models out there. As I dug deeper into the topic, I discovered dozens of proprietary services and open-source neural networks. Quick tests immediately revealed stark differences in generation quality — some models clearly underperformed compared to others. TTS Arena proved especially useful in narrowing down a shortlist of promising candidates — it's a community-driven platform where people vote and directly compare different models.
Key Features to Evaluate in TTS Models
Voice Quality and Language Capabilities
At first glance, all the models listed above seem to handle the core task reasonably well, but the devil is in the details.
Speech realism: This is a subjective quality that's hard to describe but easy to hear. You probably wouldn't want to listen to a flat, robotic voice that randomly shifts from too loud to too quiet. Natural pauses, breathing, and expressive intonation are critical for making synthetic speech sound human.
Available voices: The number and variety of out-of-the-box voices matter. They enable product differentiation, especially if male, female, emotional, cartoonish, or accented options exist.
Prompt-based voice control: Some models allow you to control the tone or mood of the voice using text commands like "excited," "whispering," or "angry." This expands expressiveness and makes the model more versatile in real-world scenarios.
Voice cloning: The ability to reproduce a specific person's voice from a short audio clip. This is valuable for personalization, dubbing, or virtual assistants. However, the quality varies — some models require an hour of data, others only need 10 seconds, and the results are very different.
Multilingual support: The ability to speak multiple languages fluently — and ideally, mix them in a single sentence (code-switching). For example, saying an English sentence with French or Japanese words without breaking the flow or pronunciation.
Deployment, Performance, and Cost Considerations
It's also essential to take more technical aspects into account.
Latency: Crucial when generating long audio files or using the model in real-time interfaces. Some models can respond in milliseconds, while others take tens of seconds, even for short fragments.
Streaming support: The ability to start playback before the full audio is generated. This is essential for chatbots and voice assistants, where every second of latency impacts the user experience.
Open source: Can the model be deployed on your infrastructure? That's important if you need to use custom voices, avoid third-party APIs, or keep your data private.
Other valuable features include adjusting speaking rate, getting timestamps for words and phonemes, and using SSML markup to control pauses, emphasis, volume, and pitch.
Finally, cost. Prices can vary by orders of magnitude depending on the provider, which makes these details even more important when choosing the right TTS solution.
Navigating Incompatible APIs: OpenAI, ElevenLabs, Cartesia, Hume
When exploring modern TTS models, one of the first things you encounter is the inconsistency.
Some platforms only offer web demos — you copy in your sentence, hit generate, wait a few seconds, then try to remember how it sounded. Then you open another tab for a different model and repeat the process. It's manageable when you're just curious. But this gets old quickly if you're serious about evaluating or building an actual product.
The alternative is using their APIs—but even here, you hit a wall. Each one has a different interface: one requires voice="nova", another wants speaker_id="TxGEqnHWrfWFTfGW9XjX", and a third expects a model name, voice config, and a list of custom parameters. Some return raw audio, and others stream it in chunks. You spend more time adapting to each interface than comparing what matters — the sound.
That's where the idea behind UTTS (Universal interface to test and compare text-to-speech models) came from.
I wanted a simple way to send the same prompt to different models and get back audio, without opening ten browser tabs or learning ten APIs. At this point, UTTS isn't built for high-throughput inference or full-feature parity. It's designed to answer one question fast: which voice sounds better for your use case?
The interface is intentionally minimal:
from IPython.display import Audio
import utts
client = utts.UTTSClient(
openai_api_key="...",
elevenlabs_api_key="...",
...
)
openai_audio = client.openai.generate('Hello, world!')
elevenlabs_audio = client.elevenlabs.generate('Hello, world!', utts.elevenlabs.Voice.RACHEL)Building UTTS: A Universal Text-to-Speech Comparison Library
Feel The Vibe
I wrote the first version of the library over a couple of evenings, and AI played a major role.
From the start, the design goal was clear: make it easy to add new TTS providers without touching more than one or two files. To support this, I used the Cursor IDE as my development environment. What sets Cursor apart is its support for structured, multi-step prompting. Here's a real example of how I guided it through adding a new provider:
- "Study the repository": I ask LLM to read key files like
client.py,base.py,openai.py,elevenlabs.py, andutils.py, and summarize the architecture. - "Here's a new provider": I give it a link to the TTS API docs and prompt it to reason through the integration: how to structure the adapter, test it, and what edge cases might arise — all without writing code yet.
- "You may now write code": Once the architecture is solid, I greenlight the implementation, instructing it to match the style and conventions from the rest of the repo.
With a capable model (like Claude 4 Sonnet in "thinking mode") and a well-documented API, it often gets the first implementation almost right. In parallel, I keep a Jupyter Lab notebook open to test the integration.
Type, Lint, Commit — Repeat
If you've used AI coding tools before, you know they sometimes introduce subtle bugs or stylistic drift. I wired in type checking and linting early to reduce the chance of both.
Since I write in Python — a dynamically typed language by design — adding static checks becomes essential as the codebase grows. For type checking, I use Pyright—specifically, the Cursor-integrated plugin maintained by the IDE's team. It catches the most common issues before runtime and enforces consistency across adapters.
I added ruff, a fast linter written in Rust, to avoid stylistic inconsistencies (typical when AI writes code across different files). It enforces formatting, removes unused imports, and applies over 800 rules — all in milliseconds.
The beauty of this setup is that the AI instantly sees the linter and type checker feedback as it writes. This feedback loop often corrects mistakes before I even step in.
I use UV for environment management and dependency locking. It is also Rust-based and dramatically faster than traditional Python tooling. Pre-commit, which guards against sloppy git commits with unformatted or broken code, sits on top of everything.
This toolchain dramatically speeds things up. Of course, no system is perfect—I occasionally roll back and re-run a generation. But most of the time, it feels like pair programming at 10x speed.
Wrapping Up
I tested 7 models and over 100 voices from the top of the TTS Arena rankings. The default recommendation in most circles is to use ElevenLabs, which is a solid choice.
But what truly surprised me was the performance of Kokoro — a small, open-source model that runs locally and delivers an excellent balance of quality, inference speed, and cost-efficiency. It's proof that great results don't always require heavy infrastructure or a paid API.
I was also impressed by the model and ecosystem around Cartesia, especially their voice cloning feature — it's flexible, high-quality, and free.
I've prepared a ready-to-use Colab notebook where you can quickly try out different voices and models in one place.
Contributions are welcome if you'd like to add support for more models. Check out the GitHub repo.
Comments